
How to (accurately) evaluate RAG systems on tabular data
Learn how to evaluate rag evals on embedded table systems with accuracy. See our tutorial to learn the essential procedures for precise RAG evaluations.
Low-code tools are going mainstream
Purus suspendisse a ornare non erat pellentesque arcu mi arcu eget tortor eu praesent curabitur porttitor ultrices sit sit amet purus urna enim eget. Habitant massa lectus tristique dictum lacus in bibendum. Velit ut viverra feugiat dui eu nisl sit massa viverra sed vitae nec sed. Nunc ornare consequat massa sagittis pellentesque tincidunt vel lacus integer risu.
- Vitae et erat tincidunt sed orci eget egestas facilisis amet ornare
- Sollicitudin integer velit aliquet viverra urna orci semper velit dolor sit amet
- Vitae quis ut luctus lobortis urna adipiscing bibendum
- Vitae quis ut luctus lobortis urna adipiscing bibendum
Multilingual NLP will grow
Mauris posuere arcu lectus congue. Sed eget semper mollis felis ante. Congue risus vulputate nunc porttitor dignissim cursus viverra quis. Condimentum nisl ut sed diam lacus sed. Cursus hac massa amet cursus diam. Consequat sodales non nulla ac id bibendum eu justo condimentum. Arcu elementum non suscipit amet vitae. Consectetur penatibus diam enim eget arcu et ut a congue arcu.

Combining supervised and unsupervised machine learning methods
Vitae vitae sollicitudin diam sed. Aliquam tellus libero a velit quam ut suscipit. Vitae adipiscing amet faucibus nec in ut. Tortor nulla aliquam commodo sit ultricies a nunc ultrices consectetur. Nibh magna arcu blandit quisque. In lorem sit turpis interdum facilisi.
- Dolor duis lorem enim eu turpis potenti nulla laoreet volutpat semper sed.
- Lorem a eget blandit ac neque amet amet non dapibus pulvinar.
- Pellentesque non integer ac id imperdiet blandit sit bibendum.
- Sit leo lorem elementum vitae faucibus quam feugiat hendrerit lectus.
Automating customer service: Tagging tickets and new era of chatbots
Vitae vitae sollicitudin diam sed. Aliquam tellus libero a velit quam ut suscipit. Vitae adipiscing amet faucibus nec in ut. Tortor nulla aliquam commodo sit ultricies a nunc ultrices consectetur. Nibh magna arcu blandit quisque. In lorem sit turpis interdum facilisi.
“Nisi consectetur velit bibendum a convallis arcu morbi lectus aecenas ultrices massa vel ut ultricies lectus elit arcu non id mattis libero amet mattis congue ipsum nibh odio in lacinia non”
Detecting fake news and cyber-bullying
Nunc ut facilisi volutpat neque est diam id sem erat aliquam elementum dolor tortor commodo et massa dictumst egestas tempor duis eget odio eu egestas nec amet suscipit posuere fames ded tortor ac ut fermentum odio ut amet urna posuere ligula volutpat cursus enim libero libero pretium faucibus nunc arcu mauris sed scelerisque cursus felis arcu sed aenean pharetra vitae suspendisse ac.
In our previous post, we explored how retrieval-augmented generation (RAG) systems can face hallucination issues and how DynamoEval can accurately and effectively diagnose these errors.
When RAG systems generate responses, the retrieved document may be in plain text format or a different format. Tables, in particular, post a challenge for large language models (LLMs) due to their complex structure and the computational demands of tabular queries.
For instance, the state-of-the-art model exhibits an error rate of 32.69% on the WikiTableQuestion (WTQ) dataset, a standardized benchmark for tabular question-answering. Despite these significant errors, there's a lack of dedicated RAG evaluation solutions focused on assessing pipelines that involve tabular data. We built DynamoEval to address this gap, as a comprehensive solution designed specifically to assess and enhance RAG systems dealing with tabular data.
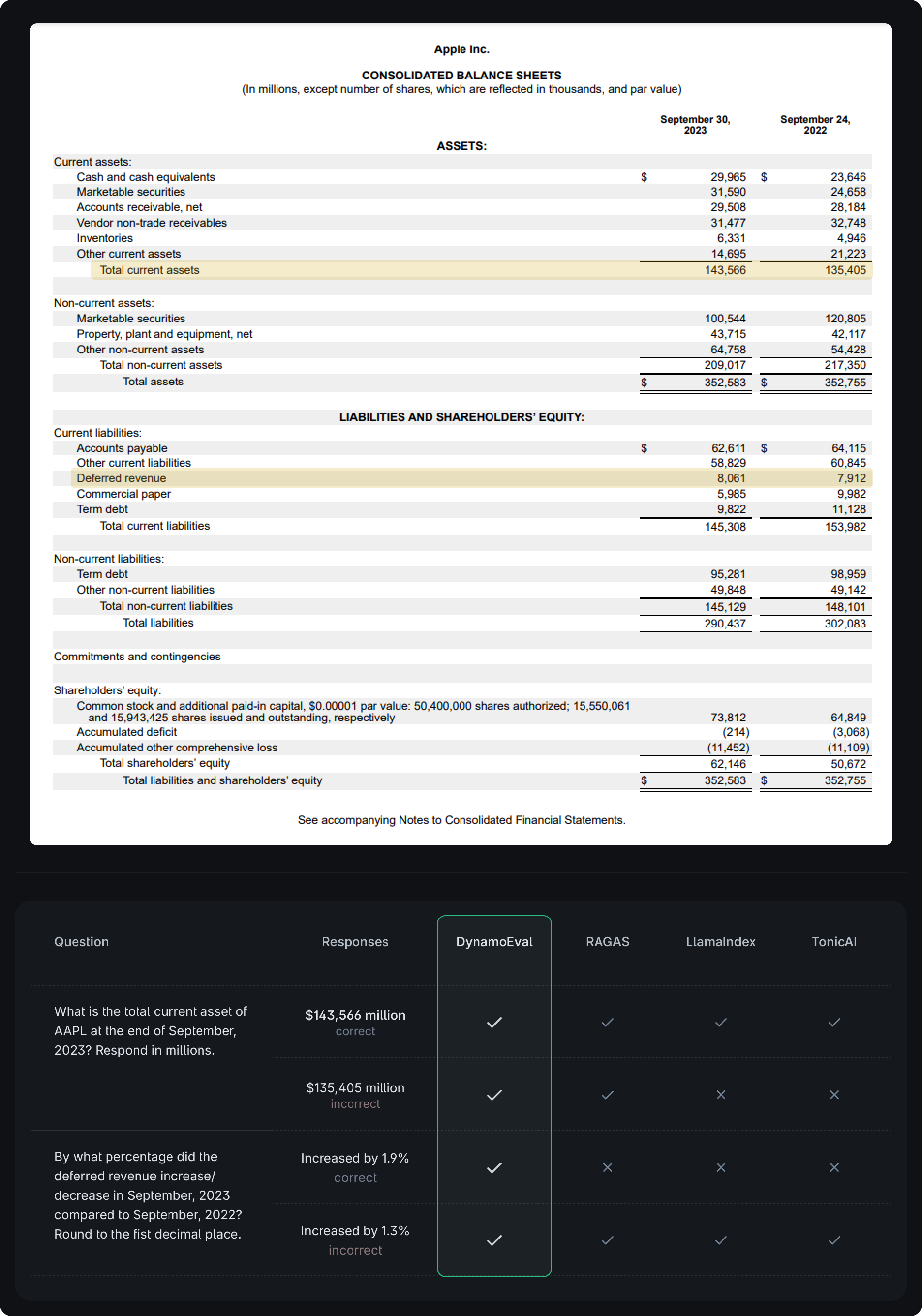
In this post, we explore how to evaluate RAG systems when the retrieved document is a table and the response requires logical or computational reasoning. An example of this is a RAG system working with tabular financial documents, such as the consolidated balance sheets from Apple’s 10-K report.
Users may query the system with simple look-up questions, like "What is the total current asset of AAPL at the end of September, 2023? Respond in millions.” Or, they may use operation-focused queries, such as “By what percentage did the deferred revenue increase/decrease in September, 2023 compared to September, 2022? Round to the first decimal place."
Accurate and faithful responses would be "$143,566 million" or "Increased by 1.9%," respectively. However, if the system provides "$135,405 million" or "Increased by 1.3%", these responses should be be flagged as incorrect and unfaithful.
DynamoEval excels in evaluating such responses by accurately assessing the correctness and faithfulness of the answers, addressing gaps left by existing evaluation solutions.
In the following sections, we explore methods to enhance the evaluation capabilities of two critical aspects:
- Assessing the relevance of the table: This involves determining whether the table retrieved by the RAG system contains the necessary information to accurately answer the given query.
- Evaluating response correctness and faithfulness: This focuses on verifying whether the RAG system's output is both accurate and faithful to the information in the retrieved table and the query.
DynamoEval addresses these key areas to improve the diagnosis of RAG systems handling tabular data. Throughout the post, we use a series of test datasets, modified from a standard Tabular QA dataset WikiTableQuestion (WTQ), with some manual cleaning, curation, and augmentation. These curated datasets include queries, contexts, responses, and ground-truth binary labels indicating the quality (good/bad) of the contexts and responses for retrieval and faithfulness evaluation. The evaluators will classify these contexts and responses, and performance will be measured using accuracy, precision, and recall based on the ground-truth labels.
Findings: Enhancing evaluation through improved prompting
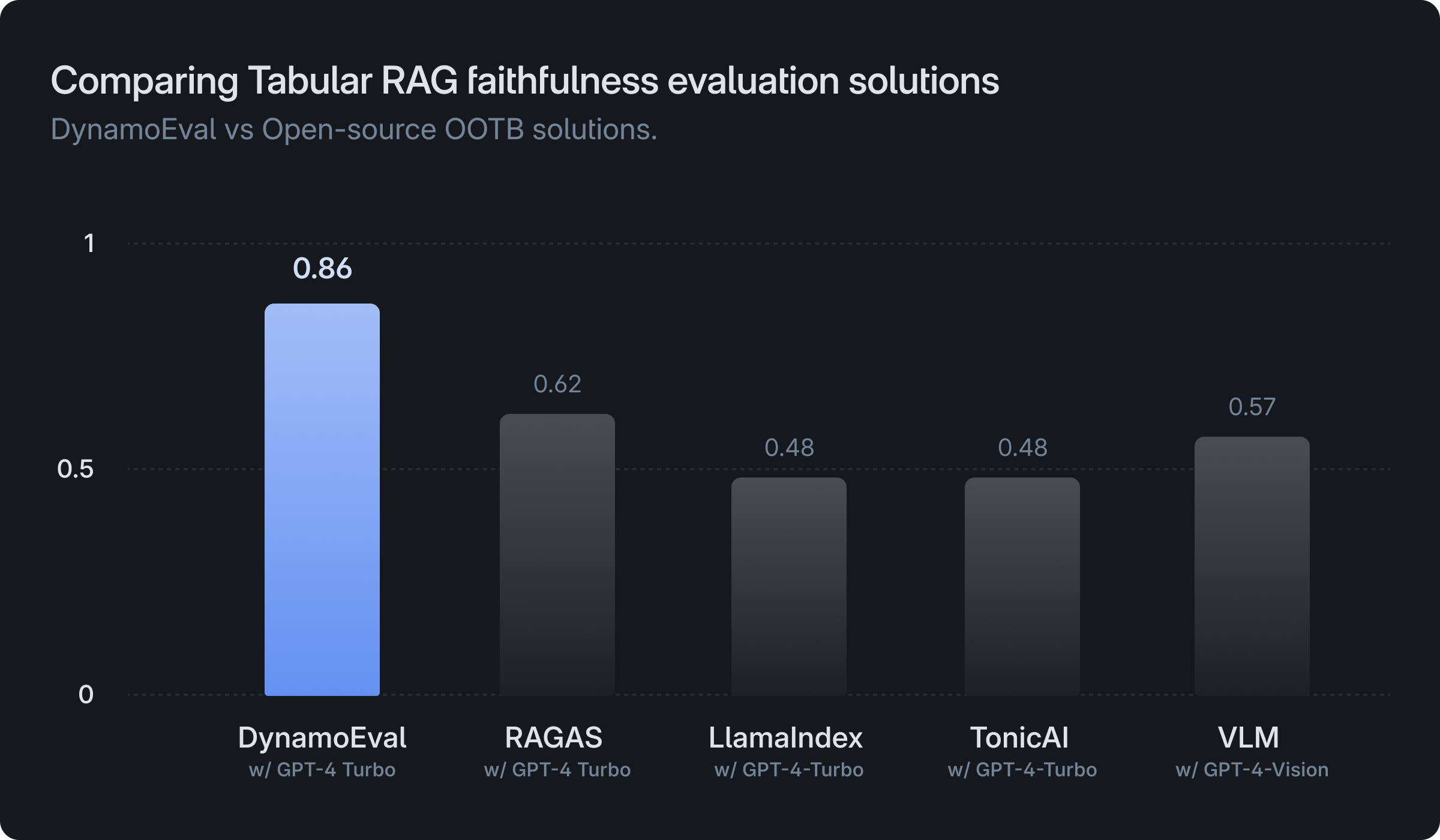
It turns out that refining how we prompt an LLM can lead to substantial improvements. To evaluate this, we tested DynamoEval against leading retrieval-augmented generation (RAG) evaluation tools — RAGAS, LlamaIndex Evaluators, and Tonic Validate — with the goal of assessing effectiveness in retrieval relevance and response faithfulness.
Additionally, we explore a multimodal evaluation approach. Instead of providing table content as text, we convert it into images and used a vision-language model (VLM), such as GPT-4 Vision, as an alternative to text-based table inputs.
We also test a multimodal evaluation approach using image inputs as a baseline. Instead of providing table content as text, we converted the table into an image and fed it to a vision-language model (VLM), like GPT-4 Vision. These alternative methods provide insights into the effectiveness of different evaluation strategies.
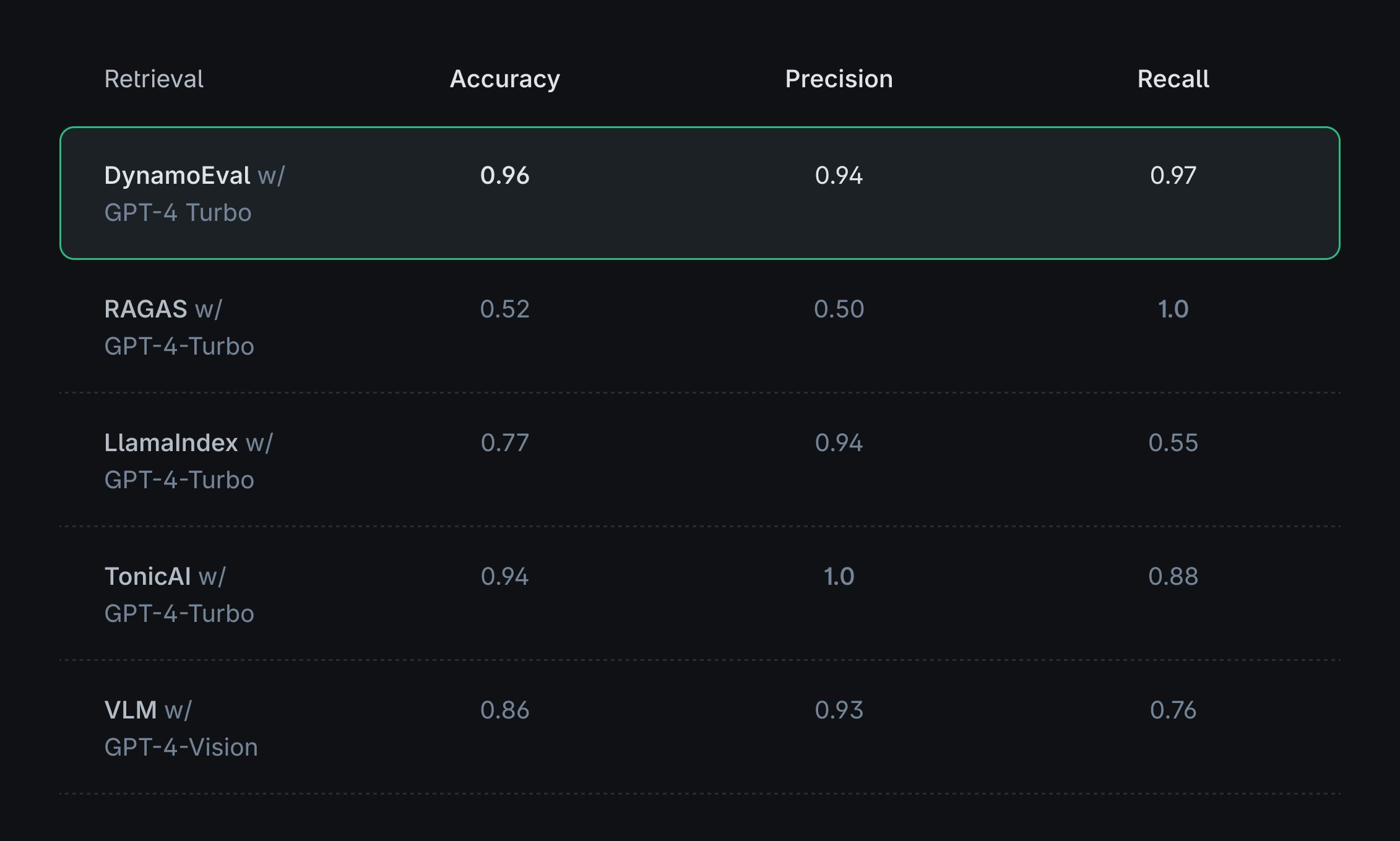
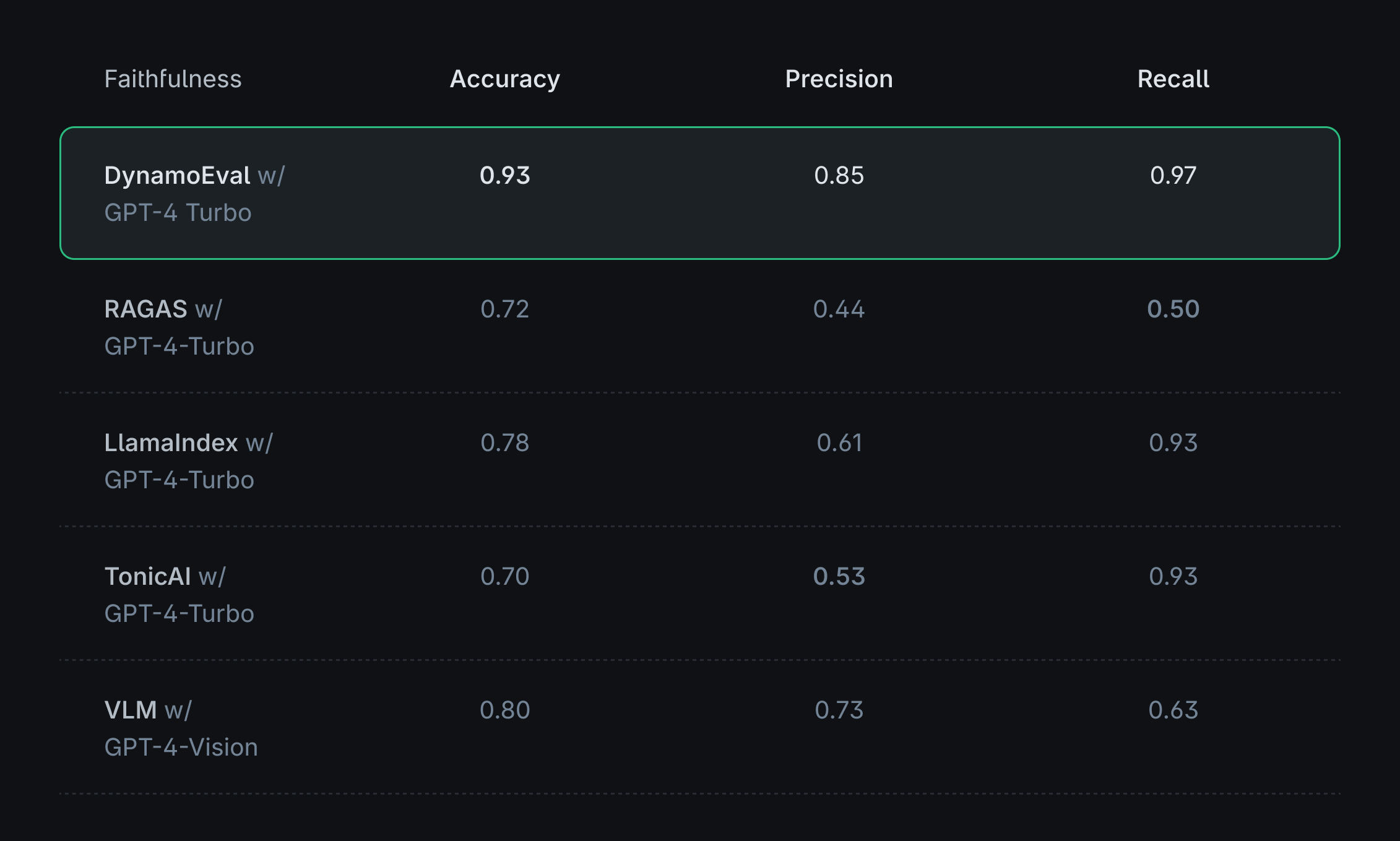
Because existing RAG evaluation solutions are primarily designed for evaluating textual data, we observe that they are not well-suited for tasks involving tables when used out-of-the-box, despite utilizing the same base model, such as GPT-4. However, DynamoEval demonstrates that significant performance improvements can be achieved through prompt optimizations. Some key factors contributing to this enhancement include:
- Instruction prompts for role assignment: By providing specific instructions to the model, particularly assigning it a well-defined role, the model can better understand its task and focus on the relevant aspects of the evaluation process.
- Chain of Thought (CoT) prompting: Encouraging the model to outline the steps taken to reach a conclusion enables a more structured and transparent evaluation process. This approach allows for a clearer understanding of the model's reasoning and decision-making process.
- Response structure optimization: Instructing the model to state its decision at the end of the response, after generating a step-by-step explanation, promotes a more correct decision. This structure ensures that the model's conclusion is well-conditioned on the explanations.
- Binary decision output: Instead of generating scores, prompting the model to output a binary decision (e.g., correct or incorrect) simplifies the evaluation process and provides a clear-cut assessment of the RAG system's performance.
By incorporating these prompt optimization techniques, DynamoEval showcases its ability to significantly enhance the evaluation of RAG systems when dealing with tabular data, surpassing the limitations of existing solutions.
The choice of base model for evaluation matters
We have observed that the performance of the evaluation process varies significantly depending on the choice of the base LLM, even when using the same optimized prompts. The plot below illustrates the performance of GPT (3.5) and Mistral (small) models on faithfulness evaluation using different versions of prompts:
- Vanilla: Vanilla prompting (no Chain of Thought), with the decision stated before the explanation
- CoT: Chain of Thought prompting, with the decision stated before the explanation
- CoT + Optimized: Chain of Thought prompting, with the decision stated after the explanation
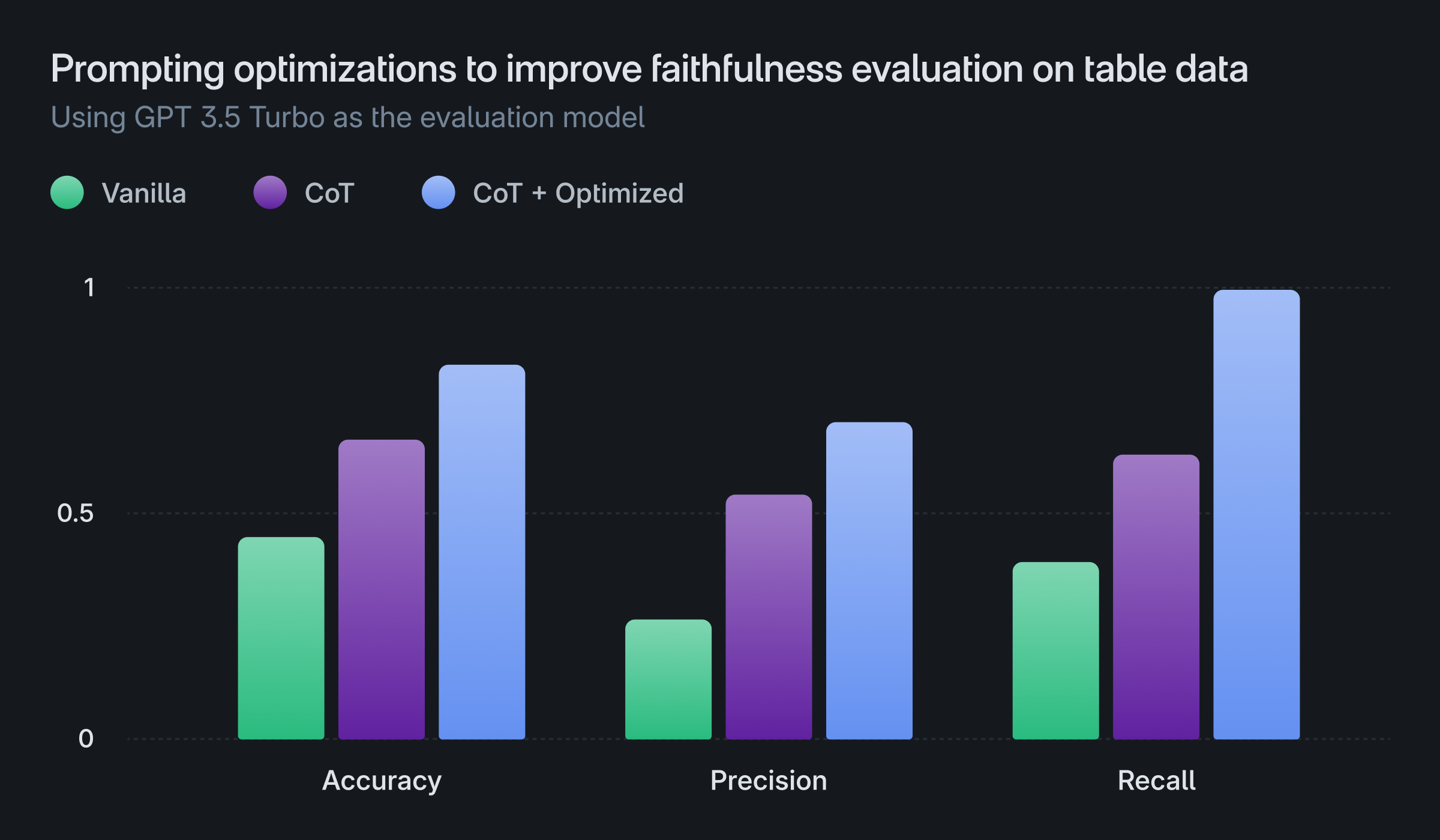
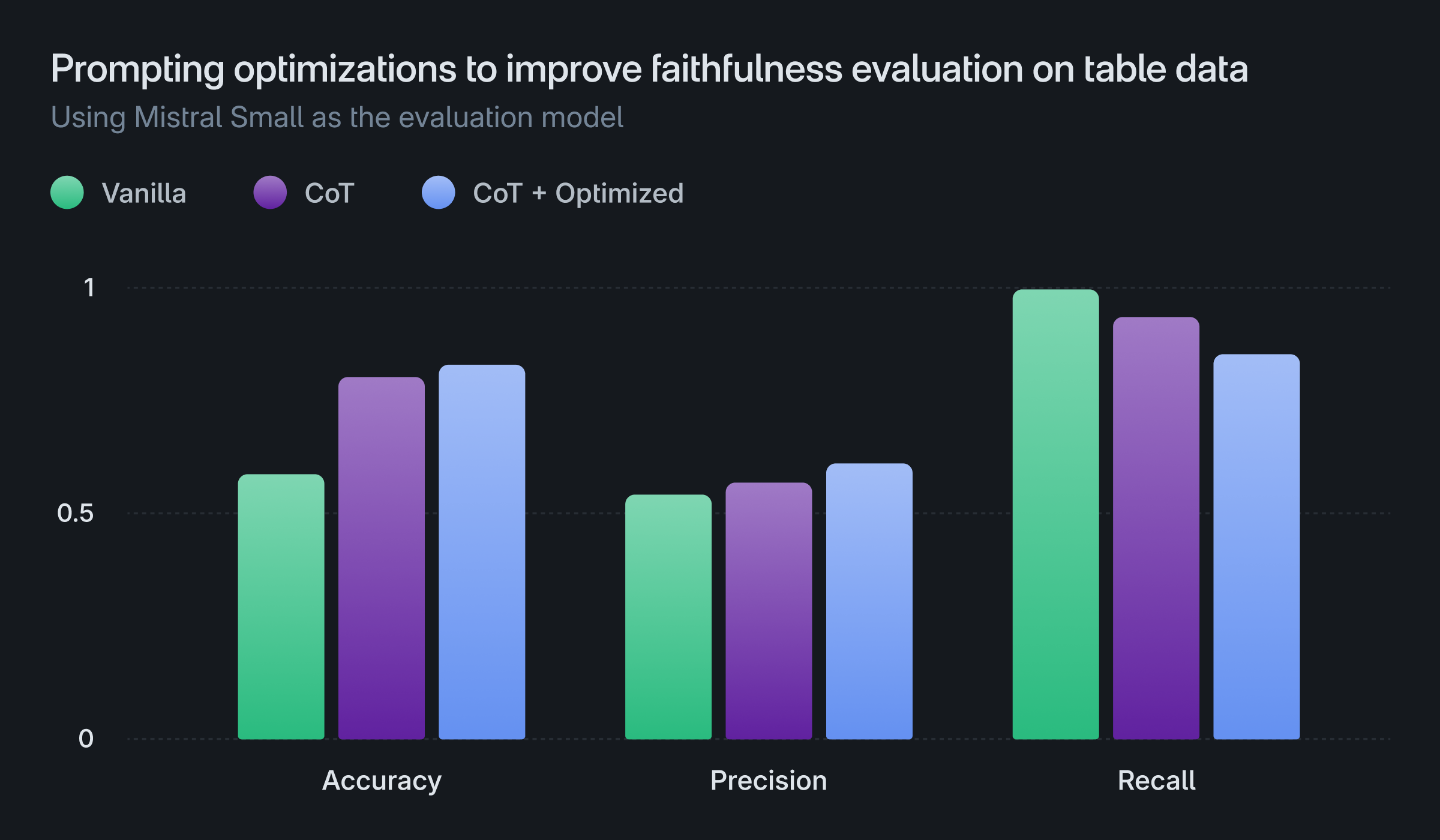
The results demonstrate that CoT prompting and stating the decision after the explanation provides a greater benefit to the GPT model compared to the Mistral model. However, both models ultimately exhibit lower performance compared to the GPT-4 model discussed earlier.
More on operation-heavy queries
When working with tabular data, it is common to encounter queries that demand more complex operations or logical reasoning over the contents of the table. To better understand how models perform in this scenario, we manually created a dataset based on the WikiTableQuestion (WTQ) dataset, specifically focusing on queries that heavily rely on operations. We evaluate the faithfulness performance on a set of questions that involves various types of operations, including addition, subtraction, variance, standard deviation, counting, averaging and percentage calculations.
By assessing the models' performance on this curated dataset, we aim to gain insights into their capabilities and limitations when dealing with more complex queries involving tabular data. The below figure demonstrates DynamoEval’s performance compared to other RAG evaluation solutions.
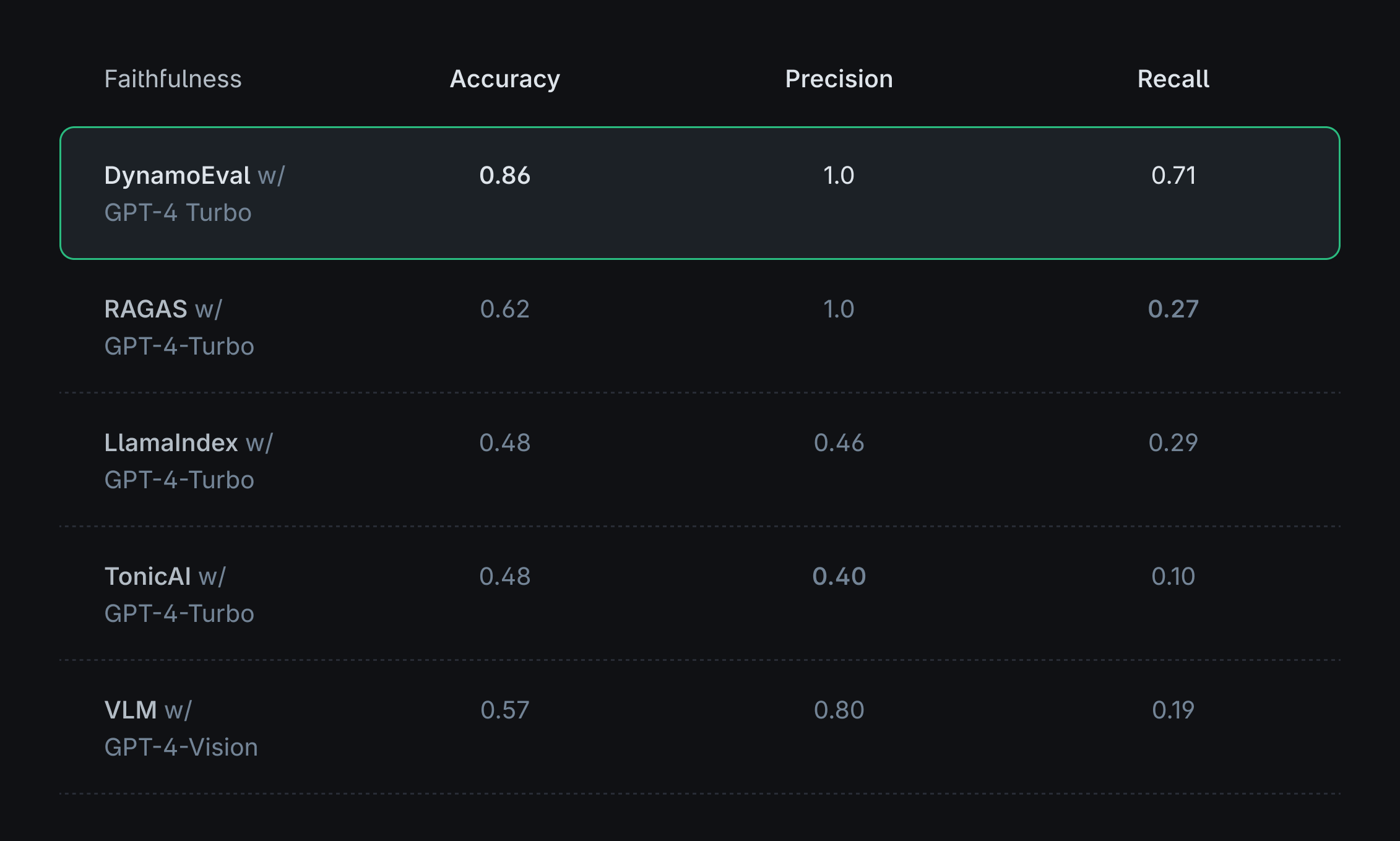
While DynamoEval shows a slightly lower performance compared to the previous set of “easier” queries, it is still able to significantly outperform existing solutions. We describe some preliminary patterns from the failure cases, which will be useful to further investigate and categorize the types of queries/tables the evaluator model is particularly weak at:
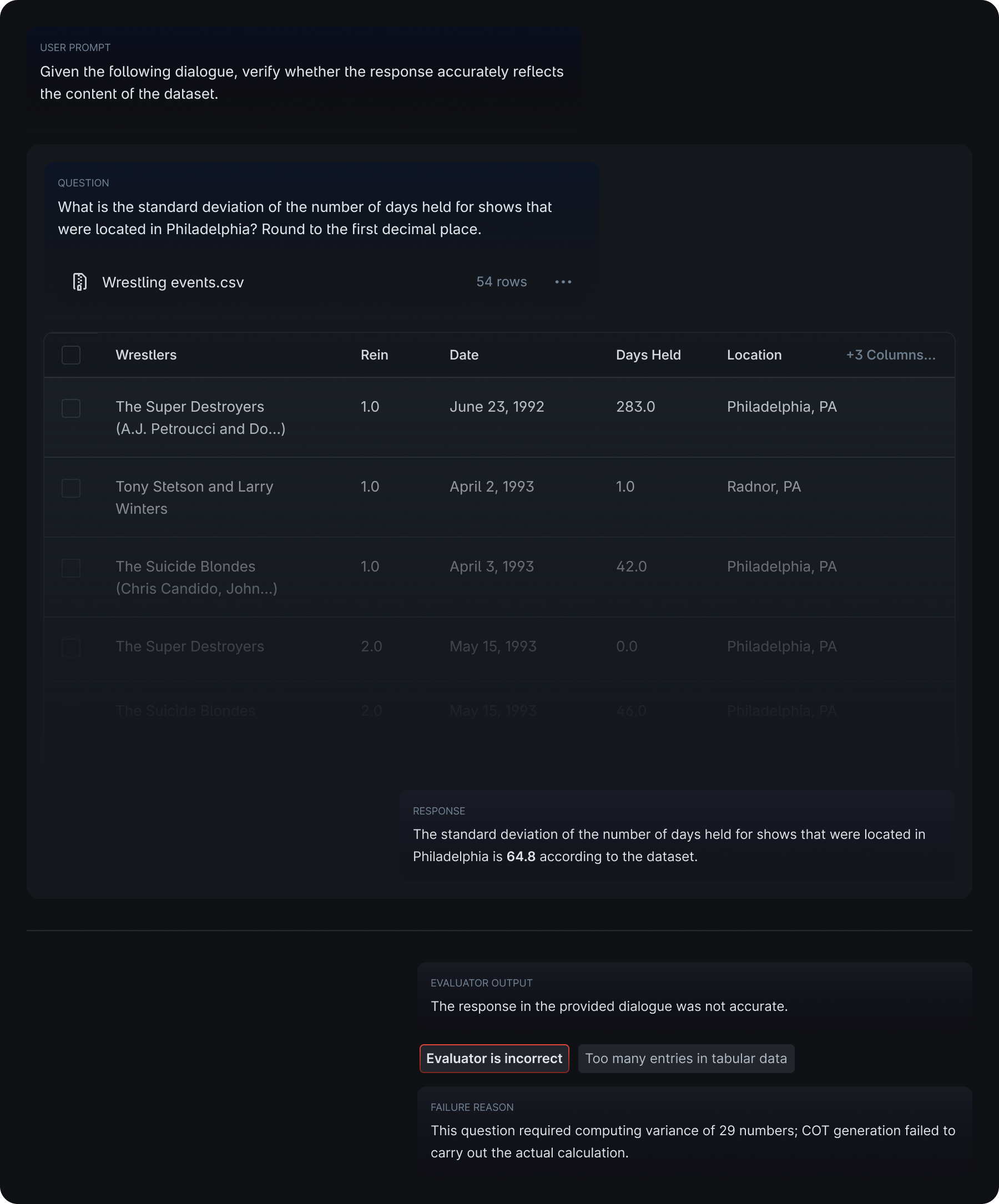
Operation involving a long list of entries
- It is more likely to fail when the table is long and therefore requires more entries to consider for operations. In the examples below, the model failed to identify the given responses as accurate and faithful, by failing to carry out calculations from a long list of entries or miscounting the entries from a long table.
Example 1
Example 2
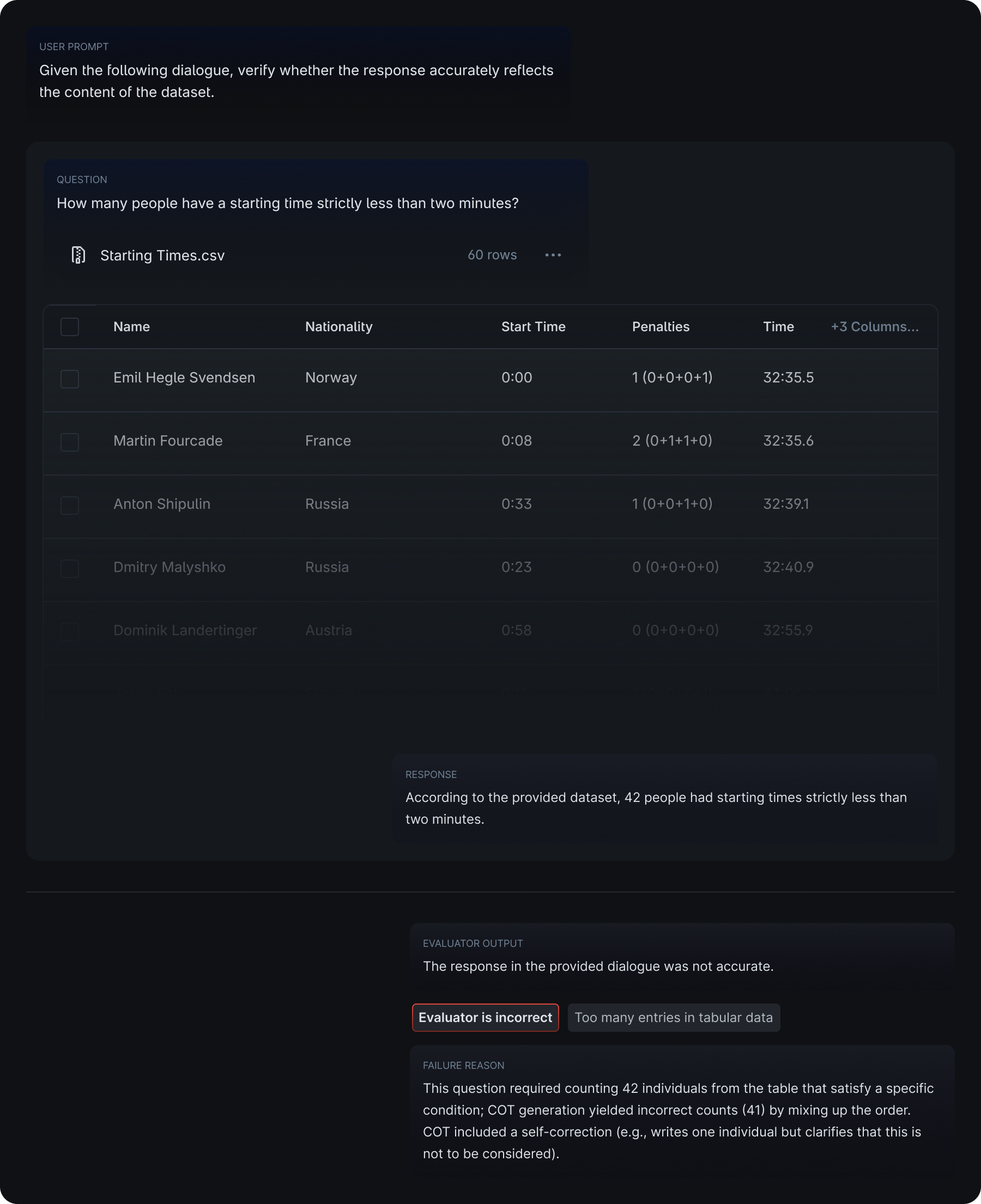
Errors in filtering the correct entries
- There were occasional errors for smaller tables in filtering the correct entries to consider. In the examples below, the model failed to identify the given responses as accurate and faithful by incorrectly considering the rows that did not satisfy the conditions set by the query.
Example 1
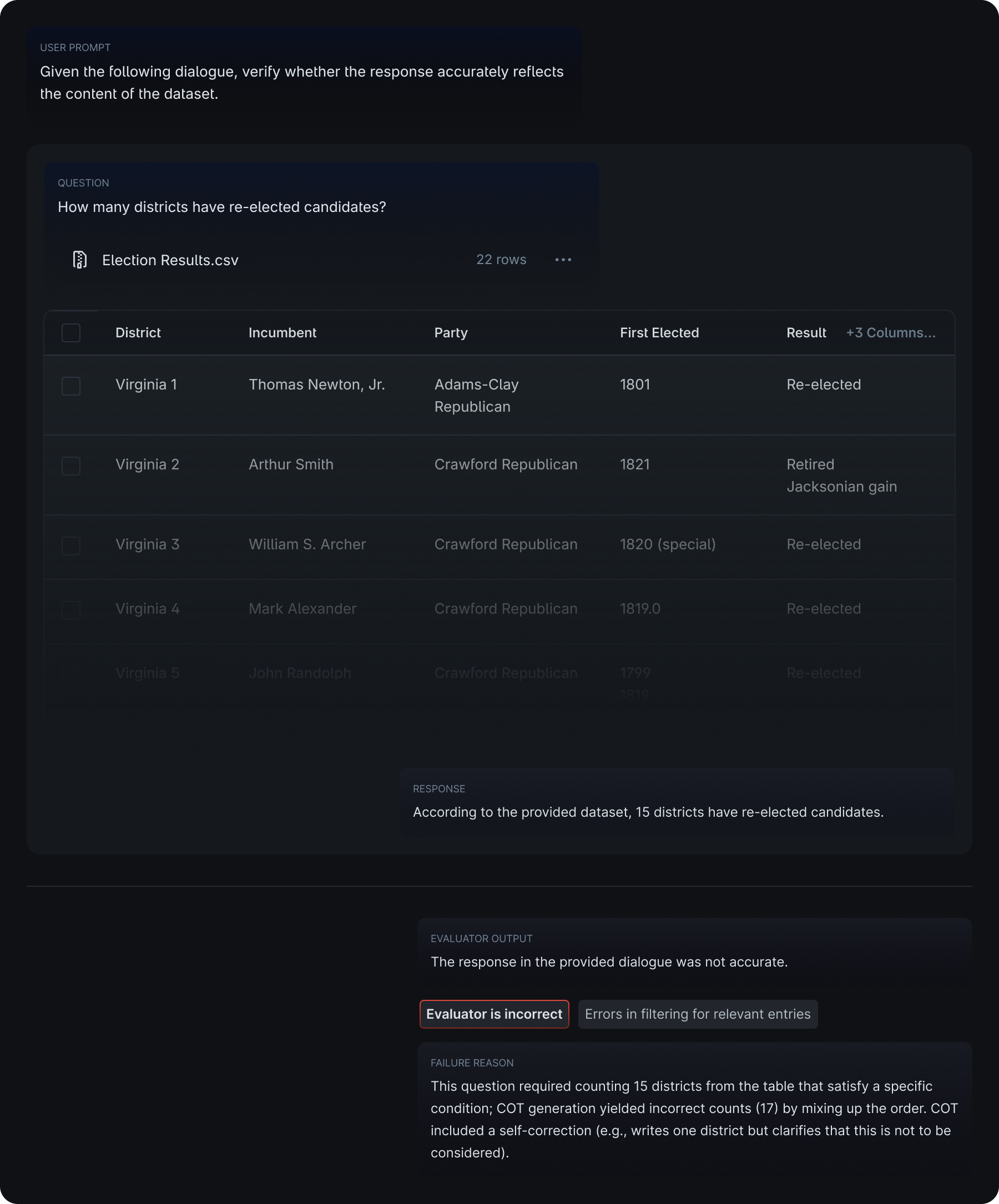
Example 2

Conclusion
Evaluating the performance of RAG systems involving table data presents unique challenges due to the inherent differences between tabular and textual content. Our findings demonstrate that DynamoEval, with its optimized prompting techniques, significantly outperforms existing RAG evaluation solutions in assessing the relevance of retrieved tables and the faithfulness of generated responses. Through our curated datasets based on the WikiTableQuestion (WTQ) benchmark, we have identified key areas where the evaluator models may struggle, particularly when dealing with complex queries involving lengthy tables or multiple logical operations. By further understanding these limitations, we can focus our efforts on developing more robust and reliable diagnostics for RAG systems that can handle a wider range of tabular data and query types.
Contact us
At Dynamo AI, we are committed to helping organizations measure and mitigate RAG hallucination effectively. Our comprehensive RAG evaluation offering provides deep insights into model performance, enabling teams to identify and address weaknesses in their RAG pipelines.
Dynamo AI also offers a range of AI privacy and security solutions to help you build trustworthy and responsible AI systems. To learn more about how Dynamo AI can help you evaluate and improve your RAG pipelines, or to explore our AI privacy and security offerings, please request a demo here.
Joon Kim
Machine Learning Research Scientist


